15 years of discovering known biodiversity
Plazi production on 23. December 2023 Source
1992 was a seminal point in the fight for biodiversity. The Rio Earth Summit put the loss of biodiversity on the top of the political agenda after pressure from scientists. With this the ball was back with the scientists to provide scientific evidence and the tools to measure the loss of diversity from genes to species to ecosystems. Required is a standardized report documenting change that can ultimately be used in the political dialogue, balancing the many interests covering the environment. An example off is offered by the assessments of the Intergovernmental Science-Policy Platform on Biodiversity and Ecosystem Services (IPBES).
30 years later, the state of biodiversity continues to be severe. Of an estimated 8 million (multicell) plant and animal species, around 1 million are threatened with extinction, and over 10% of genetic diversity of plants and animals may have been lost over the past 150 years1.
Over half of the world’s GDP (about $58 trillion) is significantly reliant on nature and biodiversity. The World Economic Forum ranks the biodiversity crisis as a top 10 global economic risk, highlighting the urgent need for action.
This is happening while we still don’t know how many species there are on Earth. In fact, we not only do not know how many species live on Earth. We even do not know how many we know, nor what we know about those we know. Most of the content in our daily expanding corpus, now estimated at 500 million pages, consisting of valuable information, is hidden in printed publications in our libraries or behind paywalls.
Things that have changed
A lot, however, has also been achieved since 1992 that gives us hope. The progress is particularly heartening during the last ten years since the launch of the Bouchout Declaration on Open Biodiversity Knowledge Management.
- Funders like the European Commission, Swiss Science Foundation and the Arcadia Fund require open access to data generated through their programs.
- Large open access based research infrastructures like the Distributed System of Scientific Collections (DiSSCo) provide digital access to their physical specimens.
- Global infrastructures like the Global Biodiversity Information Facility (GBIF) aggregate over one billion occurrences under an open license.
A lot of progress has also been achieved with regards to the tools for measuring biodiversity. DNA based sampling is becoming the dominating method for sampling species, and citizen science networks such as the Cornell Lab of Ornithology and iNaturalist provide a huge number of observations adding up to 5 million species names. Remote sensing now covers every corner of the world with data down to a few meters resolution, adding environmental information to each observation.
Organize our knowledge and make it accessible
When we collect information about plants or animals, we organize it by adding a unique identifier, using two main methods:
- Either giving them a taxonomic name in the form of a Latin binominal scientific name (if identifiable) as a unique ID.
- Or by adding a numeric code. This is applied especially for those species recognized by molecular methods that don’t have a taxonomic name yet.
While the numeric codes work well in the digital world, the scientific names can be problematic.
Specimens are identified as belonging to a particular species, whereas the taxonomic name serves as the gateway to all the published knowledge about it.
However, taxonomic names are a bit tricky to use in the modern, digital world of information. The name might mean different things to different experts, it can change over time with new research, it needs experts’ knowledge to decipher the taxonomic name and to find the knowledge. It is currently not easy for machines to explore the data behind the name. You might only find a citation of a publication, but not the actual data.
Plazi’s Mission
The goal of Plazi is to bridge this gap by promoting open access to taxonomic data hidden in scientific publications. Plazi converts taxonomic publications into digital, accessible knowledge: Understandable by humans and machines at any time, any place – for everybody.
Plazi develops tools and services that can find, convert, and store data from these publications and make them easy to use. We also support the creation of clear and consistent vocabularies, explore new ways of publishing, and provide resources to help converting scientific papers into a more accessible format. Ultimately, we want to build a global network of resources related to biodiversity, connecting information about species in a way that is easy to understand and use.
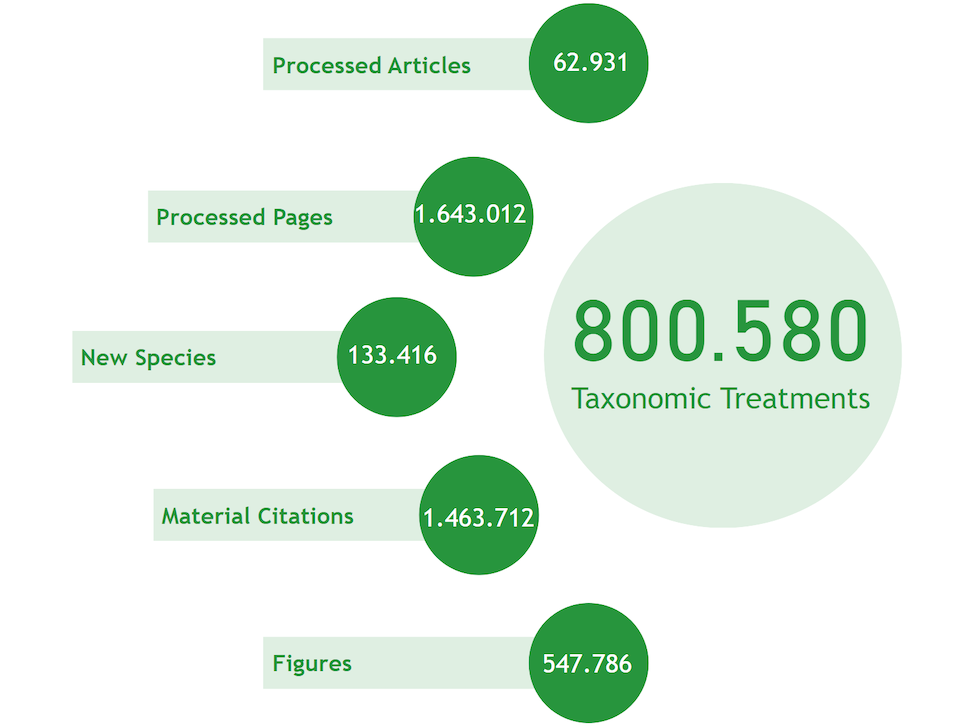
Taxonomic Treatments
What we have achieved
Over the last 15 years, Plazi built two research Infrastructures (Treatmantbank, Biodiversity Literature Repository together with Zenodo) recognized by the European Union, is spearheading the building of the biodiversity PMC together with SIBiLS and Pensoft, catalyzed access to data in publications to over 60 journals, liberated 850,000 taxonomic treatments from 620,000 taxa2, 1,450,000 material citations.
Scientists around the world are contributing to the goal of building a baseline dataset of the species we know, what we know about them and identify them, to their behavior, biotic interactions or distribution. Plazi contributes online learning resources and trainings to grow the community and get scientists involved to contribute to open up data.
Plazi has been committed to one goal since its foundation in 2008: Providing open access to this knowledge, developing and maintaining infrastructure together with other partners, and promoting access for example through the co-organization of the Bouchout Declaration on Open Biodiversity Knowledge Management which will celebrate in 2024 its tenth anniversary.
Over EUR 3 millions have been raised, including a generous support by the Arcadia Fund, to build and maintain this infrastructure.
Next steps: What needs to be done
With 15 years of activity - a long life for what started as a project - Plazi has shown what can be achieved towards open access to biodiversity knowledge.
What is now needed is to expand this activity to convince funders, publishers, editors and authors to create digital accessible knowledge as part of their ongoing publishing activity. On the other hand, we need scaling up building tools to convert the huge corpus of legacy publication, and infrastructures to provide continuous access to and power to mine its content.
This enormously rich digital accessible knowledge will allow its use beyond biodiversity, for example by its seamless integration with biomedical knowledge to understand possible viral spillovers. It will contribute to building the reference catalog of life needed to link all knowledge about life. Finally, it will democratize science by providing equal, unlimited access to data that is mainly collected in the South and housed in the North, and allow using artificial intelligence to mine and create new insides and wealth.
-
A “taxa” (plural of “taxon”) refers to a group of one or more organisms that are classified together as a unit in biological taxonomy. ↩︎